网红之路-使用 Python 做数据调研
2020-05-30 | 日常 Python 生活 | 10 min read
此文章发表于 595 天前,请注意文章时效
这篇文章是之前老婆突发奇想,想要在一些平台上建账号,尝试「网红」之路。我寻思着既然要做内容,那怎么也得先去了解一下自己内容在这个平台上的现况吧,比如这个话题的活跃度、发文量之类的。
想了一下怎么去实现,找专业的调研机构是不太可行了,没有钱。那就只能自己做,然后我想了一下,觉得直接使用平台上的搜索功能,搜索自己需要的话题,然后统计文章数量与时间关系,大体上就可以得到时间变化曲线,应该也可以做个参考。
🦁️ 1.需求
利用平台的搜索功能,搜索自己需要的话题,并且量化之后,做出时间变化曲线。
🐶 2.思路
应该可以使用 Python 编写爬虫,然后获取某段时间内的文章,对文章的发文量、评论量、赞数进行统计做图。
- 爬虫可以使用 requests 库
- 数据做图使用 matplotlib 库
- 数据处理 pandas 与 pymongo
🛸 3.具体实施
3.1 首先分析目标网页
其实现在几乎所有的平台都有搜索功能,我这里选知乎做个例子,其它平台都大同小异,思路总是一样的。
- 对目标网页进行分析
上面的图片是知乎上搜索的页面,我随便找了个关键词就选了「python」,搜索之后,发现乱七八糟的太多了,我又选择了时间范围为「三个月内」,结果如下:
嗯,这样看上去就好多了,并且三个月,统计出来的数据也有一定的参考价值了。打开 Chrome 的「检查」页面。点击 network 选项卡,在左边寻找和搜索相关的数据包。会发现一个有 search 名字的包,如下所示:
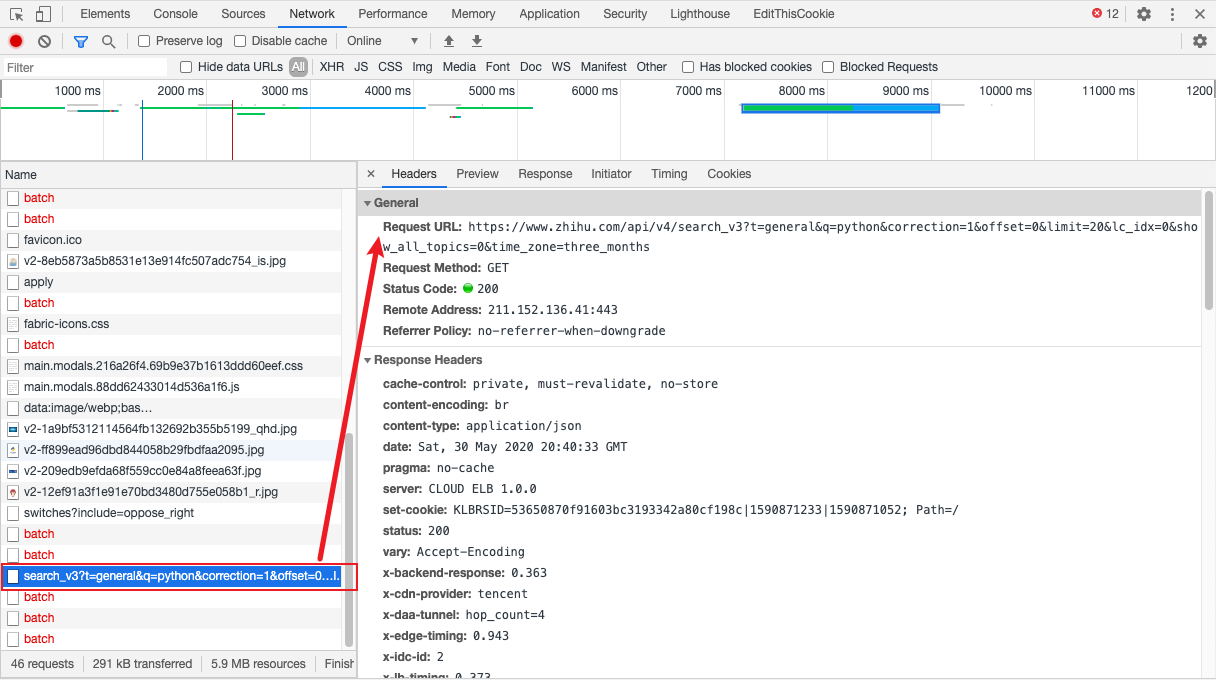
我们点击预览看看,果然就是返回的搜索结果,并且结果是 json 格式。仔细看一下请求的地址和数据
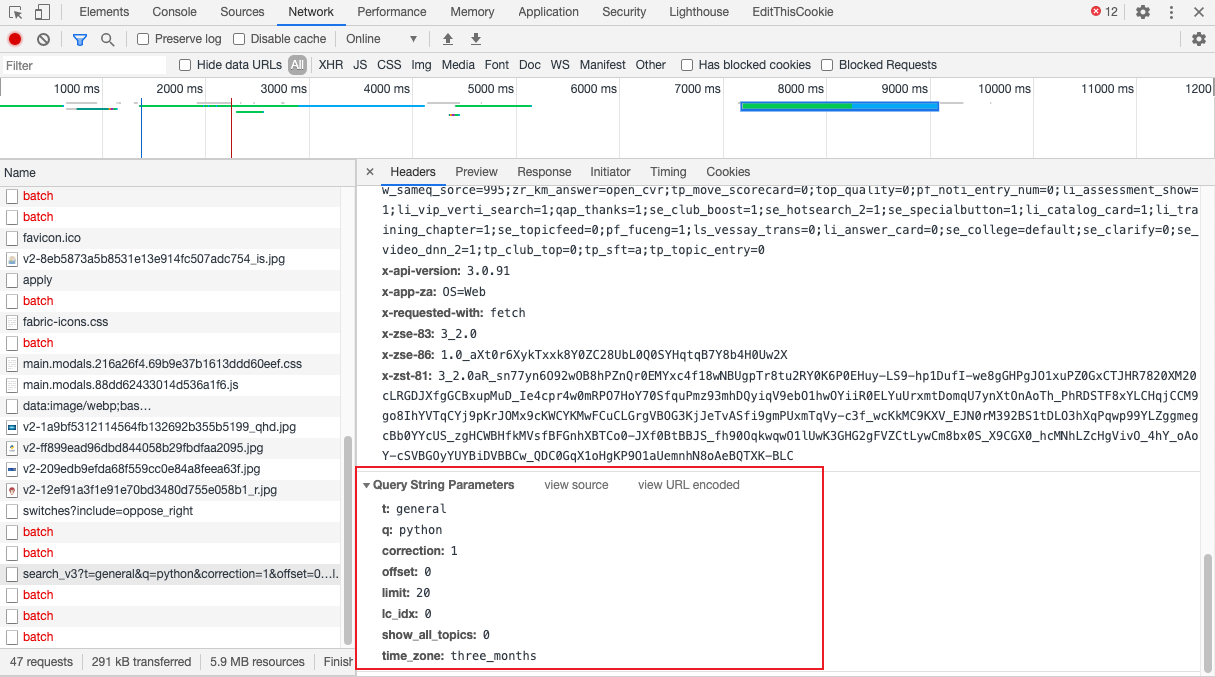
一般而言,返回结果不可能只有一页 所以我们向下滚动搜索结果页面,看看新刷新出来的结果返回什么样的数据包。向下滚动之后,不出所料果然又返回了一个新的搜索结果。
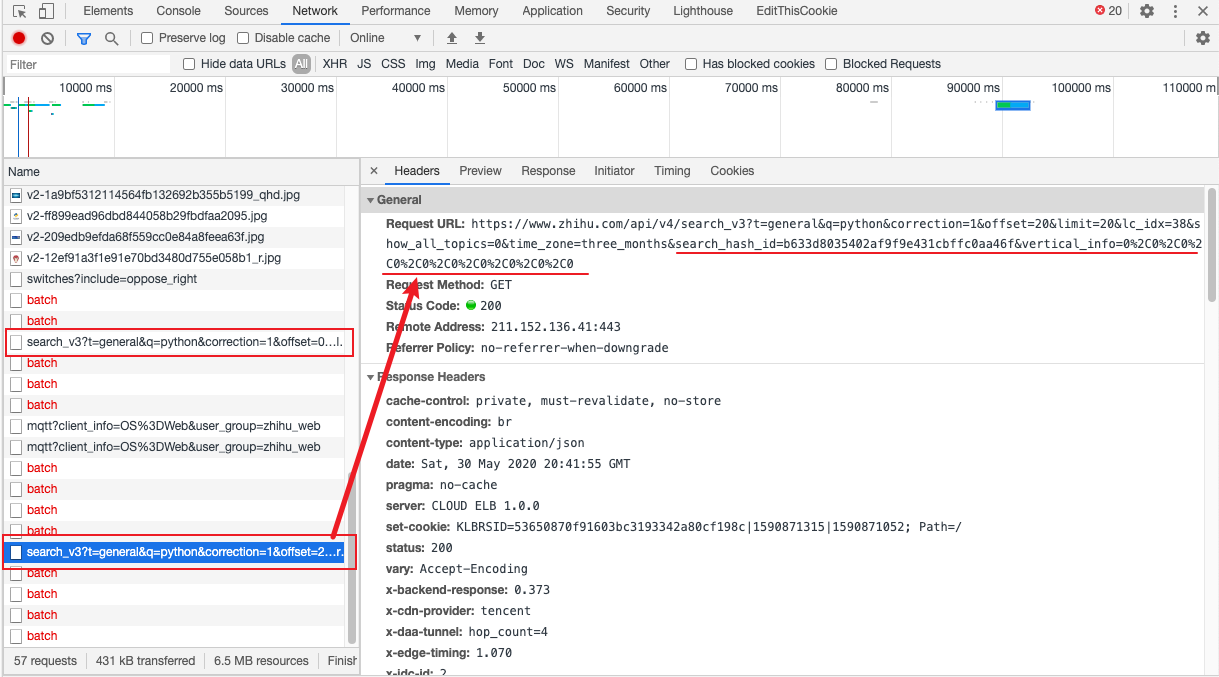
仔细看下请求的地址,发现两次请求的参数有所不同。
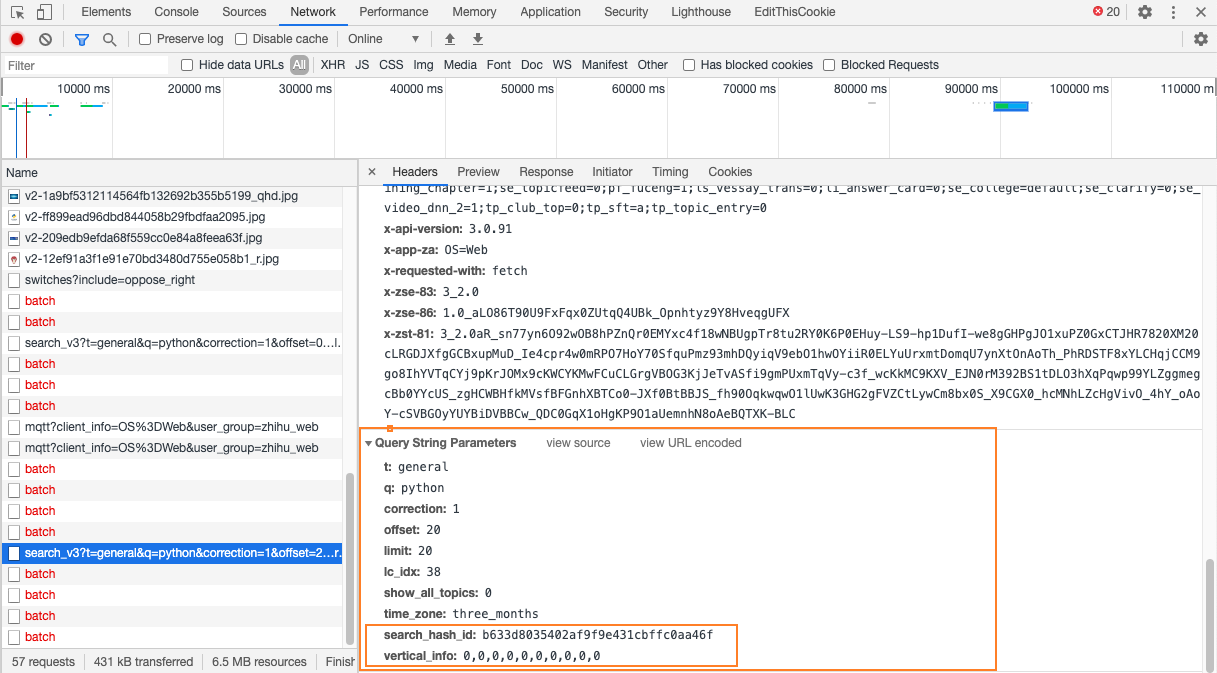
多了两个参数:search_hash_id和vertical_info
分析目标网页到这,我们已经得到需要的内容:
请求地址:https://www.zhihu.com/api/v4/search_v3?t=general&q=python&correction=1&offset=20&limit=20&lc_idx=38&show_all_topics=0&time_zone=three_months&search_hash_id=b633d8035402af9f9e431cbffc0aa46f&vertical_info=0%2C0%2C0%2C0%2C0%2C0%2C0%2C0%2C0%2C0
返回结果:json 格式
3.2 爬虫代码
其实大部分需要用到爬虫的地方,思路都差不多。我们得到请求的地址与返回的结果格式之后,就可以来编写代码了。
仔细分析下请求地址中的参数:
general: 是指返回综合搜索结果
q:搜索关键词
correction:不知道是什么意思
offset:搜索返回数据的偏移量
limit:每次返回的结果数量
lc_idx:不知道什么意思
time_zone:时间范围
search_hash_id:应该是此次执行的搜索行为的id
vertical_info:不晓得
有了这些理解之后,我大概就知道了如何构造请求地址了,就是循环改变 offset 的数值,从而可以不断返回新的数据。每次返回20条数据的话,offset 可以取0、20、40、……之类的数据。
请求数据
pattern = re.compile(r'\\u003c/?em\\u003e')
# remove <em> label
def handle_url(url):
headers = {
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'accept-encoding': 'gzip',
'accept-language': 'en-GB,en;q=0.9,zh;q=0.8,zh-CN;q=0.7,zh-TW;q=0.6,ja;q=0.5',
"cache-control": "max-age=0",
'cookie': '_xsrf=a21de17a-59ee-4d29-b4b9-5c397d0917ca; _zap=cce7d96b-ecd2-4953-b958-cc0bfbe9a2e7; BAIDU_SSP_lcr=https://www.google.com/; cap_id="NGM1OGZlYTgwMWU2NGI5YjgyZGQyYzJlYTIwZDYyMTc=|1587130242|8f2a774418c56fabb1f42aaf30d7e37dbd0df1a7"; capsion_ticket="2|1:0|10:1589482049|14:capsion_ticket|44:OGEzY2NkZGVjZTIzNDg2MGE1NWNkOTYwMTgxYWUzZWI=|0e51411a2863f1881abc1a57c7b1867e6b0a059464fa43e6a2e55bf97c86bc7d"; d_c0="ADCb102P-hCPTr5IshFBfxUARc-mRhjx2iY=|1584472689"; l_cap_id="MTI2ZDg3OWUxNmMwNDk2Y2ExYWI4ZjY5MDRjMGIyODQ=|1587130242|6c9a2dafefd22d23c9f19142a7fb4061ebc0f45f"; q_c1=e14ff8f74d144c4d9b4ce781405d22ca|1589200919000|1589200919000; r_cap_id="OGIzMzU4ZmVjODFhNDZkYzg3MWZhOTdhMDliYTExNDY=|1587130242|5e08cedf3450929c6b9816ca0dfef46c1248fa24"; tst=r; z_c0="2|1:0|10:1589482084|4:z_c0|92:Mi4xQWw0MEd3QUFBQUFBTUp2WFRZXzZFQ1lBQUFCZ0FsVk5aT0NxWHdDWEVhWUJXSE1BUzZuYnV6NURCSmNrNFlPNk9R|d2595436ce2f97f37b61de7c533b0415fd03bd8dc5b95c3d3199f7ab90bb5eeb"; KLBRSID=5430ad6ccb1a51f38ac194049bce5dfe|1589487035|1589486377',
'sec-fetch-dest': 'document',
'sec-fetch-mode': 'navigate',
'sec-fetch-site': 'none',
'sec-fetch-user': '?1',
'upgrade-insecure-requests': '1',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36',
}
# 我试了一下,这些 headers 好像是都需要的……没有办法减少
resp = requests.get(url, headers=headers)
clear_text = pattern.sub("", resp.text)
# 因为我发现有一些返回的标题中含有 <em> 强调标签,所以使用正则表达式,替代掉
return clear_text
我原本以为就这样轻松完成了呢,结果第二条 url 就没有办法返回数据了,但是同样的方法,第一条 url 可以返回数据,第二条就不可以。我刚开始是以为 headers 的问题,我反复尝试了不同的参数,结果还是不成,总是返回一个 error 的 json 包。
在这里,我大概花了一个多小时,直到我又重新思考请求参数的含义,发现search_hash_id可能是一个很重要的参数。既然是执行的每次搜索的 id,那是不是每次搜索都会得到一个唯一的 id, 而我在代码中使用的 id 是浏览器执行的那次搜索。我在代码中使用,会不会和自己新执行的搜索不同?
但是这个 id 是什么时候产生的呢?第一次搜索是不需要 id 的,之后每次搜索都会有这个参数。会不会是第一次搜索返回的结果中包含了这个参数呢?
于是我回头去检查了下第一次返回的结果
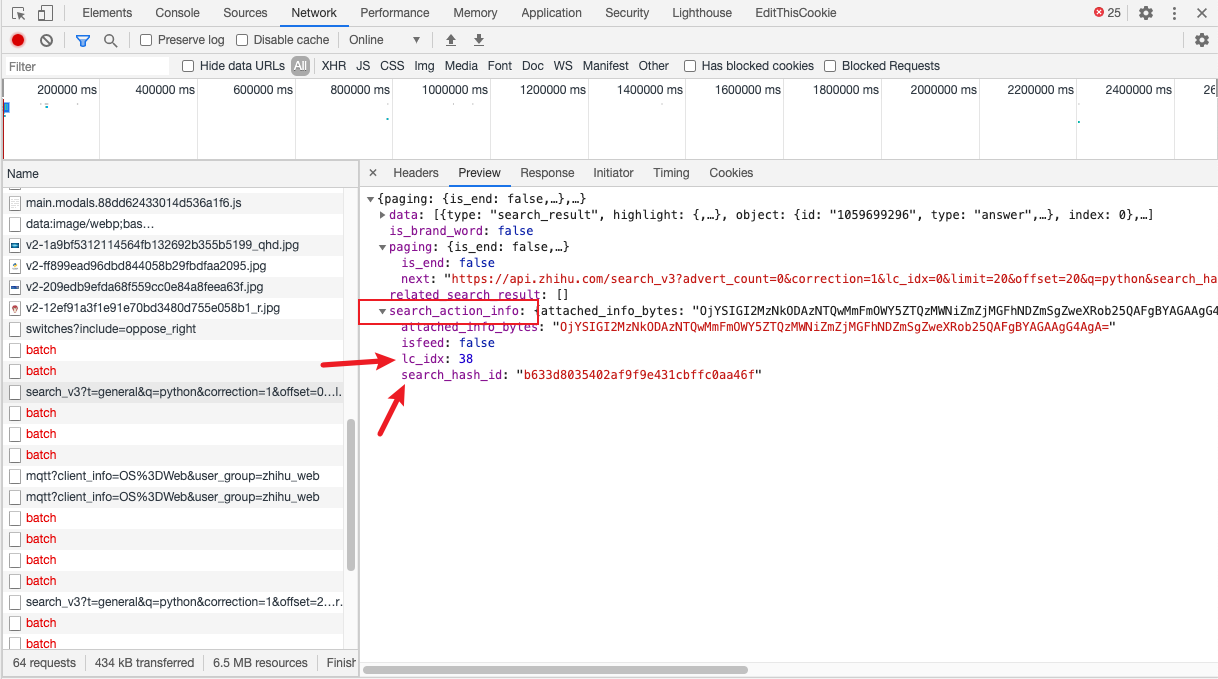
果然被我发现了,第一次返回的 json 包中含有了此次搜索操作的 id,而且我还发现 lc_idx 这个参数也是每次不同的。
思路调整
这样我调整了下思路,我需要执行一次搜索操作,从返回的结果中得到 search_hash_id和lc_idx,然后再按照规律构造请求地址。
构造请求
按照上面调整之后的思路,我这样来构造请求:
def make_url(searchid, lcid, offset):
baseurl = "https://api.zhihu.com/search_v3?advert_count=0&correction=1&"
param = {
"lc_idx": lcid,
"limit": 20,
"offset": offset,
"q": "python",
"search_hash_id": searchid,
"show_all_topics": 0,
"t": "general",
"time_zone": "three_months",
'vertical_info': '0,0,0,0,0,0,0,0,0,0',
}
url = baseurl + urlencode(param)
return url
尝试了一下,果然可以正常得到结果。但是发现一个问题:只能最多返回200条数据 开始我以为是反爬虫,但是我在浏览器中试了下,不断向下拉,刷新结果,也只能返回200条数据,换了几个关键词,也是同样的结果。
3.3 数据处理
虽然只能得到200多条数据,但是好歹也算得到了数据。数据处理就当是练手了吧
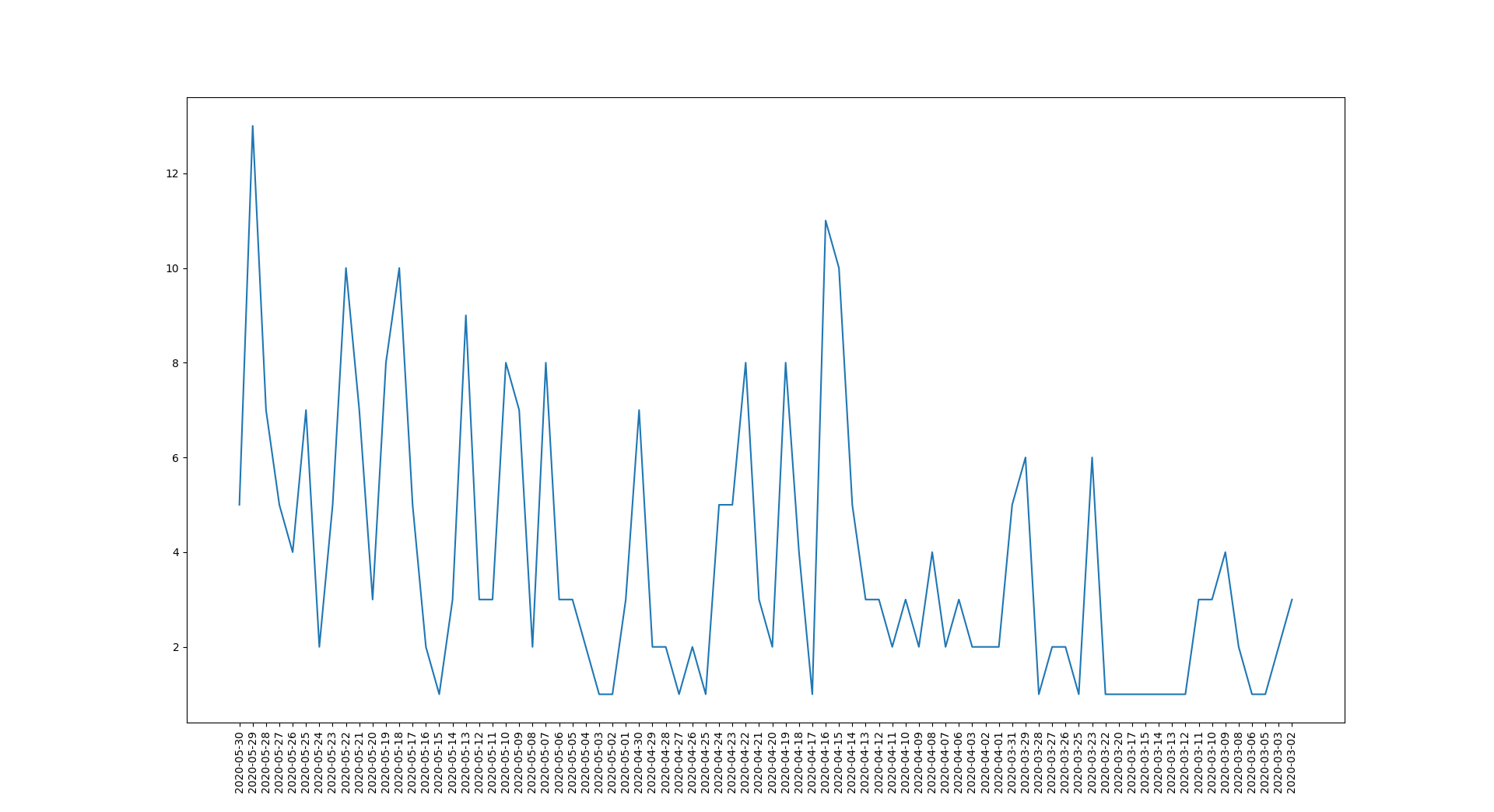
怎么处理呢?我需要知道每天这个话题的发文量,然后将发文量与时间做图,就能知道这个话题的热度变化。
代码如下:
import pymongo
import time
from matplotlib import pyplot as plt
import pandas as pd
newclient=pymongo.MongoClient('mongodb://localhost:27017')
mydb=newclient['data_research']
mycol=mydb['Zhihu']
mydata=mycol.find({})
for item in mydata:
datestamp=item['date']
local_date=time.localtime(datestamp)
date_fmt=time.strftime('%Y-%m-%d',local_date)
mycol.update_one({"date":datestamp},{'$set':{'date':date_fmt}})
# 因为得到的时间是时间戳,所以需要先将其转换了正常的时间格式,并更新数据库
x=mycol.aggregate([{'$group':{'_id':"$date",'num':{'$sum':1}}},{'$sort':{'_id':-1}}])
# 采用聚类计算,按照时间分组,并且计算每组中的数量,然后按照时间降序排列
df=pd.DataFrame(x)
x_a=df['_id']
y_a=df['num']
plt.plot(x_a,y_a)
plt.xticks(rotation=90)
plt.show()
# 转成 dataframe 之后,方便作图
3.4 最终结果
虽然因为知乎的限制,这种方式可以说是失败了,但是也算是练习了自己的技巧吧
😁 4.总结
首先吐槽一下,现在的互联网越来越封闭了,不只是知乎一家,其它家平台也是把数据都各种限制在自己的手中。从平台的角度说,这没有什么问题,我自己家的数据嘛。但是从用户的角度,或者从互联网的角度来说,每个平台就成了一个一个的小「孤岛」,原本互联网是降低用户获取信息的成本,但是现在或许连信息也获取不到了。
知乎将搜索的返回结果限制在 200 条也不知道是出于什么考虑,可能是觉得不会有人看 200 条结果?但是你也没提供任何 filter 工具呀!按时间排序、赞数排序、热度排序什么也没有。这样的搜索结果就是返回了一大堆没什么用的数据……
事后我搜索了一下,发现竟然也有人在吐槽知乎的搜索功能。为什么知乎的搜索功能如此之烂?
好了,不说了,总之这此数据调研没有成功 😂️😂️😂️😂️😂️😂️
本文链接:https://willisfusu.github.io/post/zhihu-sosuo/
此文章由李二先生采用知识共享署名-相同方式共享 4.0 国际许可协议进行许可,转载请注明出处。